Kafka Confluent
What is Kafka Confluent?
Kafka is a data broker that comes with features such as data retention, topics, clustering and the ability to release data under specific periods of time, etc. Confluent on the other hand is a wrapper built around Kafka the offers a cloud-based data streaming service utilizing Kafka as its core component
In other words, Kafka is an open-source distributed event streaming platforms that enables you to access store and stream data from one endpoint to another. The process of uploading data onto Kafka is known as producing whereas any device that receives the data is known as consuming.
Take for example a device that collects data from "WeatherAPI", it will publish (produce) the data into Kafka and then an EC2 instance connected to that cluster will consume (subscribe to) the provided data.
What is a cluster?
A cluster is a group of brokers band together to create groups of topics per broker hence making a large space where there may be sub sections to sub sections, etc. This enforces fault tolerance, high throughput and scaling, hence ensuring maximized performance
When a cluster is created the following is completed:
- A cluster of brokers are put together
- Each broker contains multiple topics
- Hence making each broker a sub-category for a series of other sub-topics
What is a topic?
In Kafka, a topic is simply a logical channel where events and data are stored. These topics are sub-divided into partitions that enable parallel processing and scalability. A device could either publish/produce data into these topics or simply subscribe to/consume data from them
The main feature of Kafka is the fact that you can have data/messages stored under topics in an instance, each topic may be a different collection of messages. The general architecture of a topic based layout may look like the following:
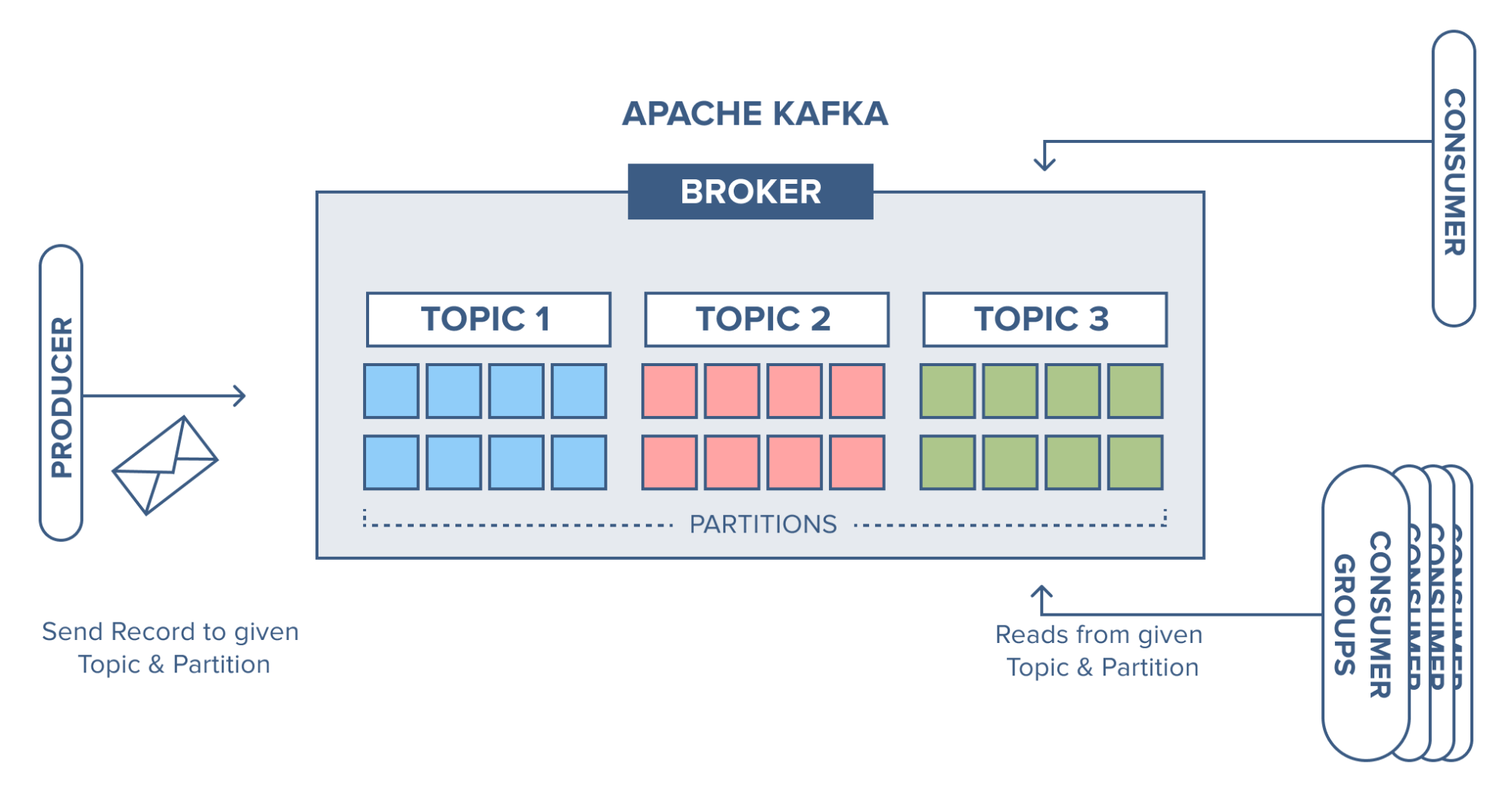
In a broker, there may be multiple partitions, each of which may be assigned to a specific topic in the broker to store a different category of messages. One of the main benefits of storing data here is the fact that there may be data retention periods, specifying how long data may be stored in a topic until it is cleared
Conclusion
To conclude and cover all the most important terms and features in Kafka, regard the following table:
| Component | Description |
|---|---|
| Producer | Application that publishes data into a topic in Kafka |
| Topics | Logical category of messages stored on kafka |
| Partitions | Each topic can be broken down into partitions to enable parallel processing |
| Brokers | Servers that store and manage partitions |
| Consumers | Applications that read and subscribe to topics on a broker |
| Consumer Groups | A set of consumers that read from the same topic collaboratively |
| Data Retentions | Brokers ability to store messages in topic for given period of time |
| Some of the major enhancements that may be made to a confluent based instance include the following: |
| Feature | Purpose |
|---|---|
| Schema Registry | Ensures data consistency using Avro, JSON Schema, or Protobuf |
| Kafka Connect | Simplifies integration with databases, cloud storage, and APIs. |
| ksqlDB | Allows real-time SQL-based event stream processing. |
| RBAC & Security | Supports authentication (OAuth, LDAP), encryption (TLS), and fine-grained access control. |