Machine Learning Operations
What is MLOPS
Machine Learning Operations take into consideration the ETL pipelines, deployment manners and machine learning components of a normal workflow. This regards architectures and basic ingestion pipelines.
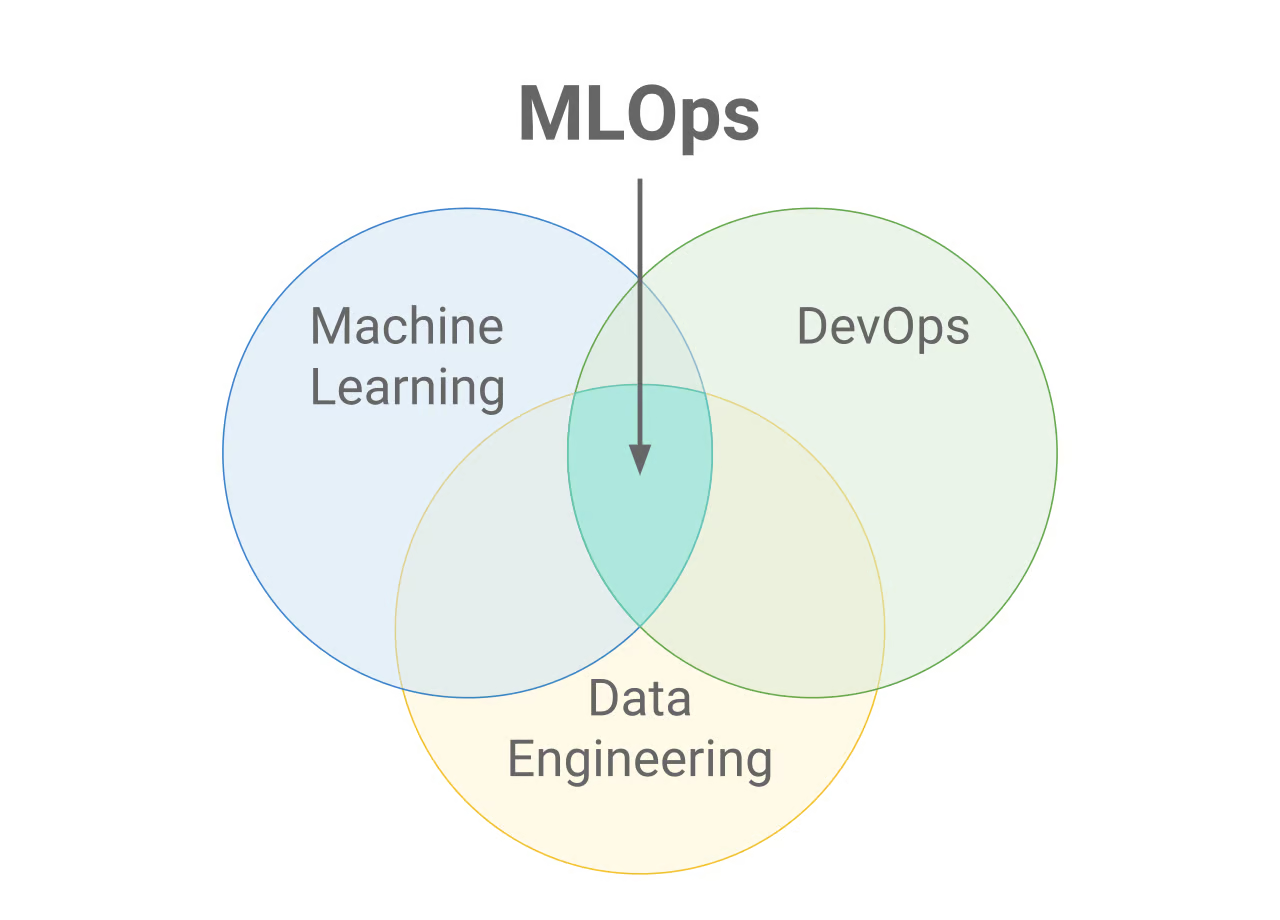
MLOps is basically a combination of data engineering, DevOps and Machine learning as to where an engineer is tasked with developing the ETL framework for a project while taking into consideration sub domains such as data retention, backups and other such features.
MLOps vs DevOps
Both MLOps and DevOps take an iterative approach to shipping applications into production, however MLOps prioritize deploying machine learning models in a deployable stage by considering all the aspects required to implementing it
In other words the key differences between MLOps and DevOps is that:
- MLOps specialize in machine learning model based deployments
- DevOps specialize in shipping applications of any kind into production
In MLOps there is an important process called CI/CD (continuous integration, continuous delivery). It is a practice that refers to the ongoing process of recognizing issues, reassessing them and updating machine learning models autonomously. The process of CI/CD negates the need to constantly, manually, update machine learning models to keep up with new trends and data. The following is an example of a CI/CD pipeline:
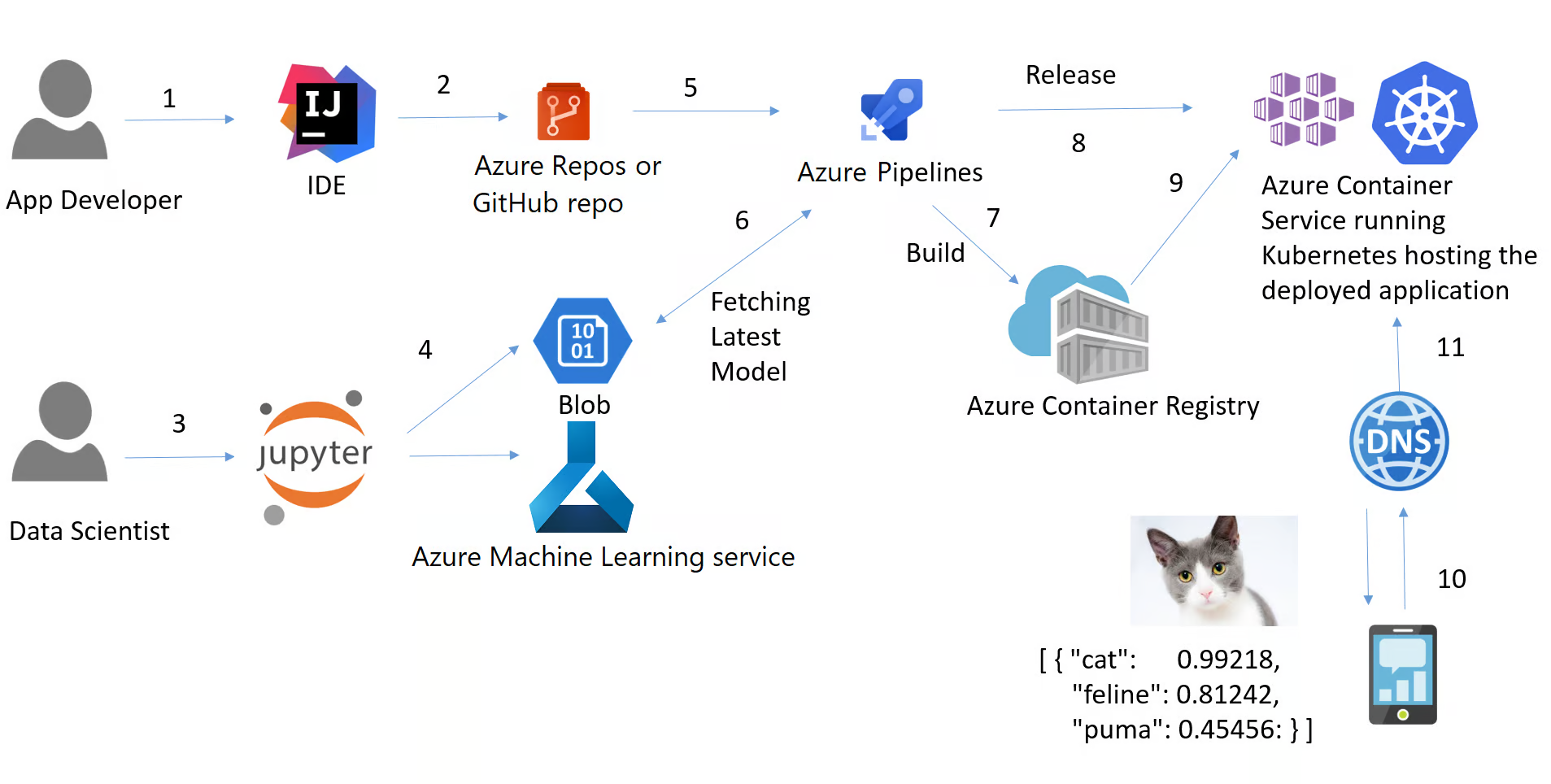
ML Pipeline against an ETL pipeline
In a machine learning pipeline, the flow is similar to an ETL pipeline, however its core components differ given the fact that the data being intake has to be validated before being processed and the deployed towards the end of the pipeline
Refer to the following image to see an example of a ML pipeline:
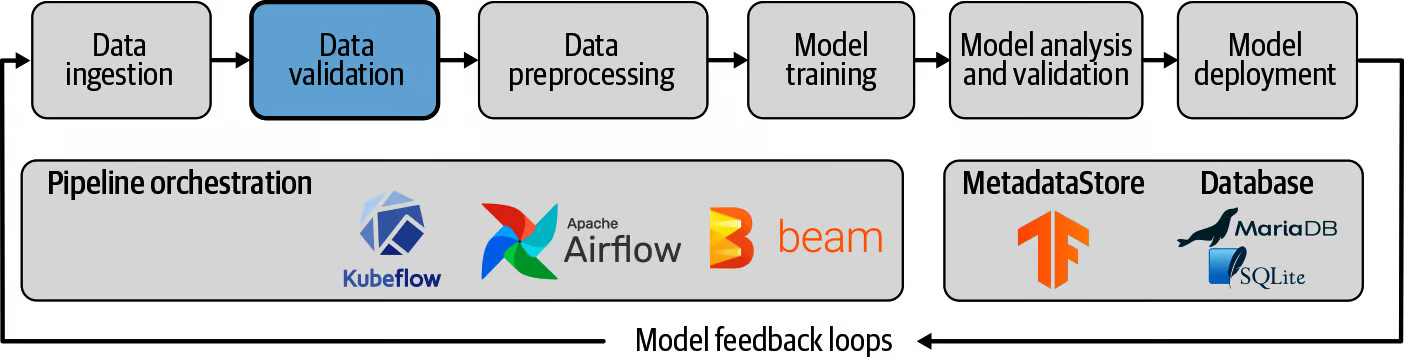
- Data Ingestion - Portion where data is collected from a source and fed into the system
- Data validation - Checks to see if the data collected is from the correct source and is of the expected format
- Data Pre-processing - Data curation, removing outliers, managing missing values, carrying out an EDA to curate the dataset, feature engineering, etc
- Model Training - Simply training the model with the curated data
- Model Analysis and validation - Carrying out cross validation scores to assess most optimal model, evaluating classification reports and model performances to ensure it is at a deployable level
- Model Deployment - Setting the model up onto AWS hosting services
Compared to machine learning pipelines, there are also data orchestration pipelines. Here instead of creating an ingestion flow with data transformation in the middle to a model there will instead be a pipeline to simply orchestrate where the data is to be collected from, how it should be transformed and where it should end up. The following are the main three types of scenario's:
| Scenario | Primary Persona | Azure Offering | OSS Offering | Canonical Pipe | Strengths |
|---|---|---|---|---|---|
| Model Orchestration (machine learning) | Data Scientist | Azure Machine Learning Pipelines | Kubeflow Pipelines | Data-> Model |
Distribution Caching, code-first reuse |
| Data Orchestration (Data Prep) | Data Engineer | Azure Data Factory Pipelines | Apache Airflow | Data-> Data |
Strongly typed movement, data centric activities |
| Code & App orchestration (CI/CD) | App Developer/Ops | Azure Pipelines | Jenkins | Code+Model->App/Service |
Most open and flexible activity support, approval queues and phases with gating |
Deployment
This regards the process of deploying and implementing a product into a system that can be accessed by end consumers. In terms of machine learning model pipelines, this would mean being able to consume the data made through an API.
In short, Deployment in Machine Learning is the method by which you integrate a machine learning model into an existing production environment to make practical business decisions based on data. It is the last stage in the machine learning lifecycle.
Application Programming Interface (API)
An API acts as an intermediary (middle man), that provides a user with access to a system data. It enables applications to communicate with each other. In other words, when provided with a pre-defined input, the API will respond with an expected outcome
Machine learning models may be accessed through API's as it provides an interaction based interface to access the outcomes of the model. In most cases the output may be in the form of a .json file, etc. Refer to the following image to see how most API's access machine learning models:
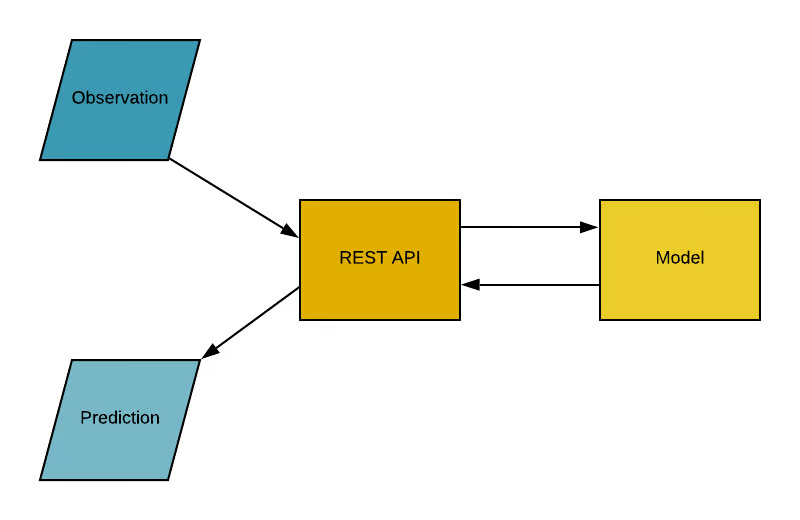
The model above shows that an observation is fed into the REST API (e.g django), which then communicates with the model to get a prediction.